Recently, a series of concurrent works, Flow matching (Lipman et al., 2023), Rectified Flow (Liu et al., 2023), and Stochastic Interpolants (Albergo et al., 2023), proposed a new class of generative model based on Continuous Normalizing Flow (CNF), which we will refer to as Flow Matching (FM) based models. In principle, FM is a more flexible alternative to the current state-of-the-art Diffusion Models (DMs), and can be viewed as a generalization of DMs in two important ways:
- Trasport between arbitrary distributions:
DM requires the base probability distribution to be Gaussian. FM allows base distribtion to be any arbitrary distribution (e.g., image distribution). This can enable many applications such as image-to-image translations. - Arbitrary probability paths:
Path followed by DM is just one of the infinitely many possible probability paths that could be attained using FM models. This is important because it allows for flexible, application-specific designs of probability paths such as optimal transport path.
Normalizing Flow
FM can be seen as a subclass of the general flow based generative models. A flow model aims to transport a base distribution \(\rho_0\) to a target distribution \(\rho_1\), both defined over \(\mathbb{R}^d\), using a transport map \(\Psi: \mathbb{R}^d \to \mathbb{R}^d\), i.e., \[ \text{if } x_0 \sim \rho_0, \text{ then } \quad \Psi(x_0) \sim \rho_1. \] A popular framework, called the Normalizing Flow, learns such a transport map \(\Psi\) using maximum likelihood objective to learn a data distribution \(\rho_1\) by fixing the base distribution \(\rho_0\) to be a simple distribution, e.g., Gaussian, that is amenable to easy sampling and density evaluation. The objective of normalizing flow follows from the change of variable formula for probability density function as shown below: \[ \max_{\Psi} \quad \mathbb{E}_{x \sim \rho_1} \log p_{\Psi}(x):= \log \rho_0(\Psi^{-1}(x)) + \log |\det J_{\Psi^{-1}}(x)| \] As one can see, the above objective involves computing the determinant of the Jacobian of the inverse of the transport map \(\Psi\). For general functions \(\Psi\), this is a computationally prohibitive operation, especially for high-dimensional data. To avoid this expensive computation, \(\Psi\) is parameterized with a sequence of simple invertible transformations such that the Jacobian determinant is easy to compute. This restriction limited the expressiveness of normalizing flow models, consequently limiting their performance compared to other generative models such as GANs.
Continuous Normalizing Flow (CNF)
CNF uses a continuous time perspective of the aforementioned transport process. Consider a continuous time dependent map \(\Psi_t\) for \(t \in [0,1]\) such that \([\Psi_1]_{\# \rho_0} = \rho_1\) and \([\Psi_0]_{\# \rho_0} = \rho_0\), a time-dependent velocity field, \(v_t: \mathbb{R}^d \to \mathbb{R}^d\), and corresponding time-dependent probability path \(p_t: \mathbb{R}^d \to \mathbb{R}_{>0}\). The vector field \(v_t\) is related to the transport map \(\Psi_t\) via the following ordinary differential equation (ODE): \[ \frac{d}{dt} \Psi_t(x) = v_t(\Psi_t(x)). \] And the time-dependent probability path \(p_t\) is related to end distributions via: \[ p_t = [\Psi_t]_{\# \rho_0} \]
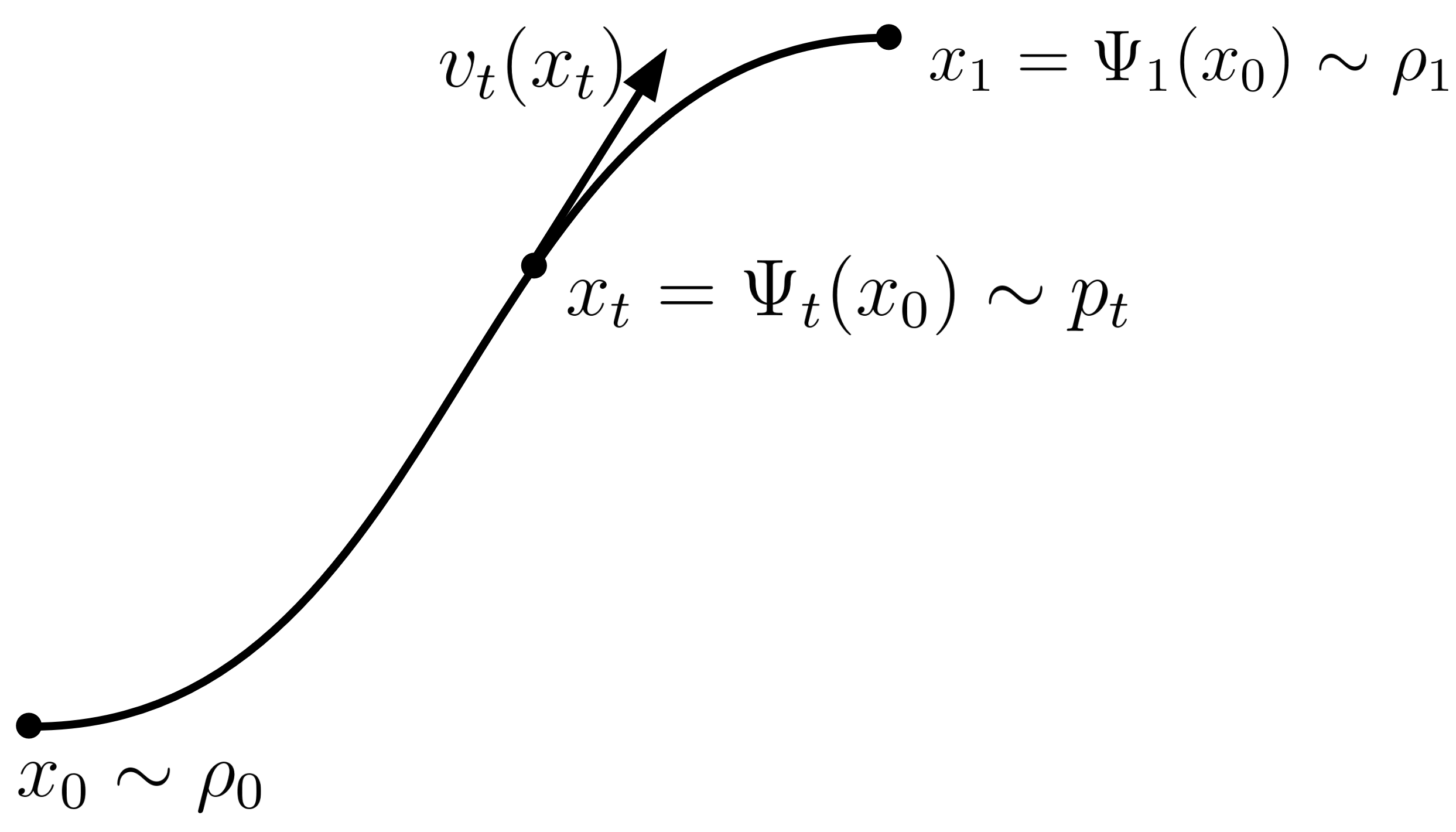
Mass Continuity Equation
A velocity field \(v_t\) results in the probability path \(p_t\) if and only if it satisfies the mass continuity equation: \[ \frac{\partial p_t}{\partial t} + \nabla \cdot (p_t v_t) = 0. \] This equation follows from Gauss's divergence theorem by enforcing probability mass conservation. Basically, one can use this equation to verify if a vector field \(v_t\) generates a given probability path \(p_t\), or to even find such a vector field (which is what we will do).
Flow Matching (FM)
Given a probability density path \(p_t\) with \(p_0 = \rho_0, ~p_1 = \rho_1 \), and corresponding vector field \(u_t\), the flow matching objective is to minimize the following loss function: \[ \mathcal{L}_{\rm FM}(v_t) = \mathbb{E}_{t \sim \mathcal{U}([0,1]), x \sim p_t} \|v_t(x) - u_t(x)\|^2. \] \(\mathcal{L}_{\rm FM}\) is simple but intractable in practice as it requires access to two quantities that we have no prior knowledge on: (i) samples from \(p_t, \forall t\) and (ii) the vector field \(u_t\). In the following sections, we will discuss how to solve the two problems, (i) and (ii), to make the flow matching objective practical.
Stochastic Interpolant
In (Albergo et al., 2023), the authors define a time differentiable interpolant function \[ I_t:\mathbb{R}^d \times \mathbb{R}^d \to \mathbb{R}^d, ~t \in [0,1]\] such that \[ I_{t=0}(x_0, x_1) = x_0, \quad I_{t=1}(x_0, x_1) = x_1.\] A typical example of \(I_t\) is the linear interpolant: \[ I_t(x_0, x_1) = (1-t)x_0 + tx_1.\] Next, a joint distribution (coupling) \(\rho(x_0, x_1)\) is chosen such that \[ \int \rho(x_0, x_1) dx_0 = \rho_1(x_1), ~ \text{and } ~ \int \rho(x_0, x_1) dx_1 = \rho_0(x_0).\] The independent coupling \( \rho(x_0, x_1) = \rho_0(x_0)\rho_1(x_1)\) is a special example that satisfies the above conditions. The final tractable flow matching objective takes the following form: \[ \mathcal{L} = \mathbb{E}_{t, (x_0,x_1) \sim \rho(x_0,x_1), x = I_t(x_0,x_1)} \left\|v_t(x) - \frac{\partial}{\partial t}I_t(x_0,x_1) \right\|^2 \] For the linear interpolant \(I_t(x_0,x_1) = (1-t)x_0 + tx_1\) and independent coupling the above objective becomes: \[ \mathcal{L} = \mathbb{E}_{t, x_0 \sim \rho_0, x_1 \sim \rho_1, x = (1-t)x_0 + tx_1} \left\|v_t(x) - (x_1 - x_0) \right\|^2 \] The above objective is very simple to implement: one just needs to randomly sample a \(x_0\) and \(x_1\) from the two datasets, a time stamp and regress the vector field at \(I_t(x_0,x_1)\) with a vector pointing from \(x_0\) to \(x_1\). At first glance, it almost seems too simple and naive: how can matching the vector field with random directions recover the desired vector field \(u_t\)? The short answer is that, in expectation, these random directions will recover the desired vector field \(u_t\). To understand why this is the case, the following section will guide you through the detailed proof.
Proof:
In previous section, we discussed that the flow matching objective \(\mathcal{L}_{\rm FM}\) is intractable due to two reasons: (i) sampling from \(p_t\) and (ii) estimating \(u_t\). In this section, we will discuss how addressing these two issues results in the tractable and simple flow matching objective \(\mathcal{L}\).(i) Sampling from \(p_t\)
Then, \(x_t = I_t(x_0,x_1)\) defines a stochastic process \(x_t\) (hence called stochastic interpolant), given samples from \((x_0,x_1) \sim \rho(x_0,x_1)\). Probability path \(p_t\) induced by \(x_t\) is a valid time dependent probability path for constructing a CNF because when \( (x_0,x_1) \sim \rho(x_0,x_1)\), \[ I_0(x_0,x_1) = x_0 \implies p_0 = \rho_0, \quad I_1(x_0,x_1) = x_1 \implies p_1 = \rho_1.\] Therefore, the procedure for sampling from \(p_t\) is straightforward:- Sample \((x_0,x_1) \sim \rho(x_0,x_1)\)
- Compute \(x_t = I_t(x_0,x_1)\). \(x_t\) is our required sample.
(ii) Estimating \(u_t\)
Obtaining \(u_t\) is a bit long, but not difficult to follow. First, note that we can express \(p_t\) using Dirac delta function as follows: \[ p_t(x) = \int \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1,\] where \(\delta_{I_t(x_0,x_1)}\) is the Dirac delta function centered at \(I_t(x_0,x_1)\). We know that our desired velocity field \(u_t\) corresponding to \(p_t\) should satisfy the mass continuity equation: \begin{align} & \frac{\partial p_t}{\partial t} = - \nabla \cdot (p_t u_t) \\ & \implies \frac{\partial}{\partial t} \int \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 = -\nabla \cdot (p_t(x)u_t(x)) \\ & \implies \int \left(\frac{\partial}{\partial t} \delta_{I_t(x_0,x_1)}(x) \right) \rho(x_0,x_1) dx_0 dx_1 = -\nabla \cdot (p_t(x)u_t(x)) \tag{1} \end{align} One important fact that will help us obtain \(u_t\) is that \(\delta_{I_t(x_0,x_1)} \) itself defines a time dependent probability path between \(\delta_{x_0}\) and \(\delta_{x_1}\). Further, \(I_t(x_0, x_1)\) is the corresponding flow that achieves this continuous transport, i.e., \[ [I_t(x_0,x_1)]_{\# \delta_{x_0}} = \delta_{I_t(x_0,x_1)} \] let us define the conditional vector field \(u_t(x | x_0,x_1)\) as \[ u_t(x | x_0,x_1) =\begin{cases} \frac{\partial}{\partial t} I_t(x_0,x_1) &\text{ if } x=I_t(x_0,x_1) \\ 0 &\text{ otherwise}\end{cases}\] Hence, by the definition of the velocity field of the flow, we have that \(u_t(x | x_0, x_1)\) is the velocity field that induces the probability path \(\delta_{I_t(x_0,x_1)}\). Hence, the pair \((I_t(x_0,x_1), u_t(x | x_0,x_1))\) satisfies the continuity equation. Therefore, \[\frac{\partial}{\partial t} \delta_{I_t(x_0,x_1)}(x) = -\nabla \cdot (\delta_{I_t(x_0,x_1)}(x) u_t(x | x_0,x_1))\] Using the above in Eq. (1), we get \begin{align*} &- \int \nabla \cdot \delta_{I_t(x_0,x_1)}(x) u_t(x | x_0,x_1) \rho(x_0,x_1) dx_0 dx_1 = -\nabla \cdot (p_t(x)u_t(x)) \\ &\implies \nabla \cdot \int \delta_{I_t(x_0,x_1)}(x) u_t(x | x_0,x_1) \rho(x_0,x_1) dx_0 dx_1 = \nabla \cdot (p_t(x)u_t(x)) \\ &\implies \nabla \cdot p_t(x) \left( \int u_t(x | x_0,x_1) \frac{ \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 }{p_t(x)}\right) = \nabla \cdot (p_t(x)u_t(x)) \\ \end{align*} The above equation implies that \[ u_t(x) = \int u_t(x | x_0,x_1) \frac{ \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 }{p_t(x)} \] is a valid velocity field that satisfies the mass continuity equation with respect to \(p_t\). Now, let's use the above expression for \(u_t(x)\) in \(\mathcal{L}_{\rm FM}\) to obtain a practical objective for flow matching as follows: \begin{align*} & \arg \min_{v_t} ~ \mathcal{L}_{\rm FM}(v_t) \\ & = \arg \min_{v_t} ~ \mathbb{E}_{t, x \sim p_t} \|v_t(x) - u_t(x)\|^2 \\ & = \arg \min_{v_t} ~ \mathbb{E}_{t, p_t} \|v_t(x)\|^2 - 2 \mathbb{E}_{t, p_t} \langle v_t(x), u_t(x)\rangle + \mathbb{E}_{t, p_t} \|u_t(x)\|^2 \\ & = \arg \min_{v_t} ~ \mathbb{E}_{t, p_t} \|v_t(x)\|^2 - 2 \mathbb{E}_{t, p_t} \langle v_t(x), u_t(x)\rangle \tag{2} \end{align*} Consider the first term in the above equation. We can express it as follows: \begin{align*} & \mathbb{E}_{t, p_t} \|v_t(x)\|^2 \\ & = \mathbb{E}_{t} \int \|v_t(x)\|^2 p_t(x) dx \\ & = \mathbb{E}_{t} \int \|v_t(x)\|^2 \int \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 dx \\ & = \mathbb{E}_{t} \int \|v_t(x)\|^2 \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 dx \\ & = \mathbb{E}_{t, (x_0,x_1) \sim \rho(x_0,x_1), x = I_t(x_0,x_1)} \|v_t(x)\|^2 \tag{3} \end{align*} Now, consider the second term: \begin{align*} & \mathbb{E}_{t, p_t} \langle v_t(x), u_t(x)\rangle \\ & = \mathbb{E}_{t, p_t} \left\langle v_t(x), \int u_t(x | x_0,x_1) \frac{ \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 }{p_t(x)} \right\rangle \\ & = \mathbb{E}_{t} \int \left\langle v_t(x), \int u_t(x | x_0,x_1) \frac{ \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 }{p_t(x)} \right\rangle p_t(x) dx \\ & = \mathbb{E}_{t} \int \left\langle v_t(x), \int u_t(x | x_0,x_1) \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 \right\rangle dx \\ & = \mathbb{E}_{t} \int \left\langle v_t(x), u_t(x | x_0,x_1)\right\rangle \delta_{I_t(x_0,x_1)}(x) \rho(x_0,x_1) dx_0 dx_1 dx \\ & = \mathbb{E}_{t, (x_0,x_1) \sim \rho(x_0,x_1), x = I_t(x_0,x_1)} \left\langle v_t(x), u_t(x | x_0,x_1)\right\rangle \\ & = \mathbb{E}_{t, (x_0,x_1) \sim \rho(x_0,x_1), x = I_t(x_0,x_1)} \left\langle v_t(x), \frac{\partial}{\partial t}I_t(x_0,x_1)\right\rangle \tag{4} \end{align*} Using Eq. (3) and (4) in (2), we get \begin{align*} & \arg \min_{v_t} ~ \mathcal{L}_{\rm FM}(v_t) \\ & = \arg \min_{v_t} ~ \mathbb{E}_{t, (x_0,x_1) \sim \rho(x_0,x_1), x = I_t(x_0,x_1)} \left\|v_t(x) - \frac{\partial}{\partial t}I_t(x_0,x_1) \right\|^2 \\ \end{align*}Note on Diffusion Model
Diffusion model (stochastic or deterministic/probability flow) can be viewed as a special case of flow matching. Consider a special instance of interpolant function \(I_t(x_0, x_1) = \alpha_t x_0 + \sigma_t x_1 \). Further, let \(\rho_0 = \mathcal{N}(0,1)\). Then Variance preserving (VP) SDE follows the probability path determined by \(\sigma_t = \sqrt{1-\alpha_t^2}\), where \( \alpha_t = \exp(-\frac{1}{2}\int_0^t \beta(s) ds) \), and \(\beta\) is the noise schedule function.
Results
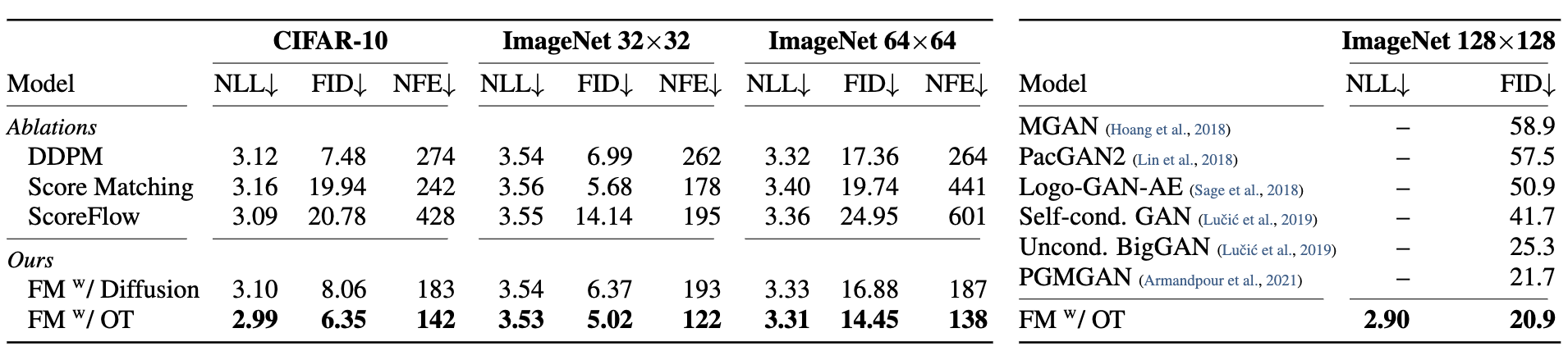
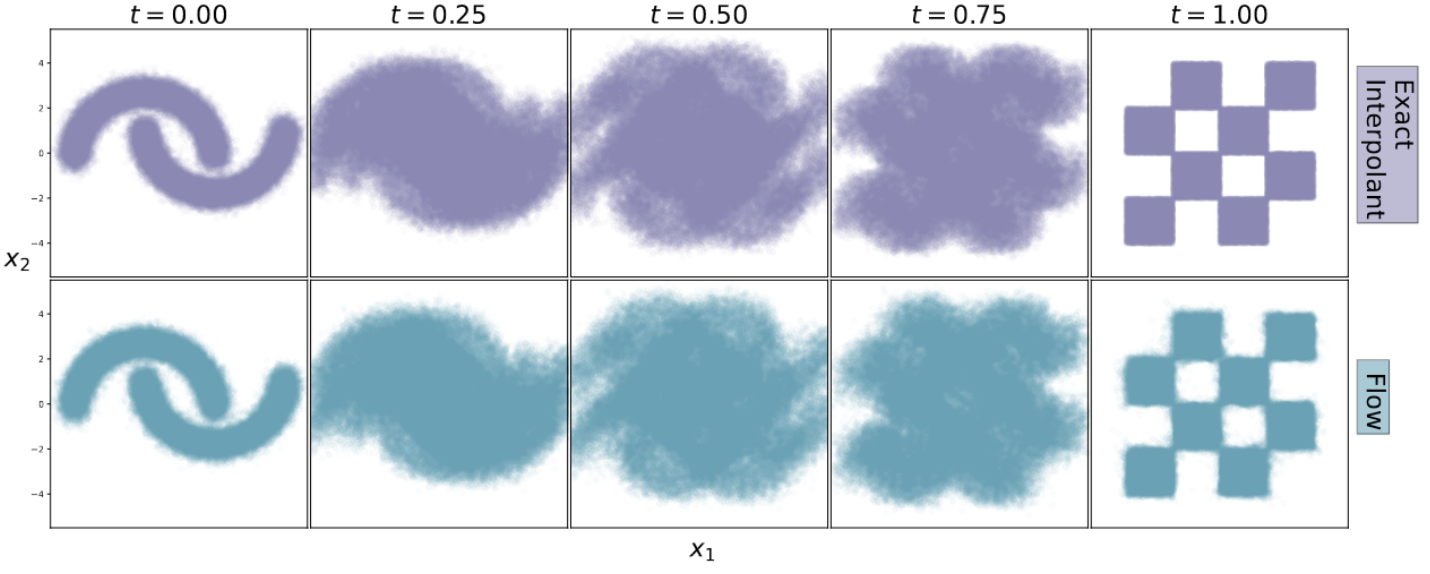


References
[Lipman et al., 2023] Lipman, Y., Chen, R. T., Ben-Hamu, H., Nickel, M., & Le, M. (2023). Flow matching for generative modeling. arXiv preprint arXiv:2210.02747.
[Chen et al., 2018] Chen, R. T., Rubanova, Y., Bettencourt, J., & Duvenaud, D. K. (2018). Neural ordinary differential equations. Advances in neural information processing systems, 31.
[Albergo et al., 2023] Albergo, M. S., & Vanden-Eijnden, E. (2023). Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571.
[Liu et al., 2023] Liu, X., Gong, C., & Liu, Q. (2023). Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003.