(The following article is derived from my reading group presentation on vision-language representation learning.)
Vision-language representation learning has emerged as a pivotal area in artificial intelligence, bridging the gap between computer vision and natural language processing. From enhancing image search capabilities to enabling sophisticated AI assistants, vision-language models are revolutionizing how machines perceive and interact with the world. In this post, we'll explore the key components and recent advancements in this rapidly evolving field, covering the state-of-the-art vision language representation learners.
To facilitate the discussion, we introduce the following notation:
- \( x, \boldsymbol{x}, \boldsymbol{X}, \mathcal{X} \) denote a scalar, vector, and matrix, respectively.
- \( x(i) \) denotes the \( i \)-th element of vector \( \boldsymbol{x} \).
- \( ( \boldsymbol{x}_n^{(t)} )_{n=1}^{N_t} \) and \( ( \boldsymbol{x}_n^{(v)} )_{n=1}^{N_v} \) denote the input text sequence, and image patches, respectively.
- \( ( \boldsymbol{h}_n^{(t)} )_{n=1}^{N_t} \) and \( ( \boldsymbol{h}_n^{(v)} )_{n=1}^{N_v} \) denote the corresponding text and image embeddings.
Unimodal Representation Learning
Given an image domain \( \mathcal{V} \) (or a text domain \( \mathcal{T} \)), the goal of unimodal representation learning is to learn an encoder \( \boldsymbol{e}^{(v)}: \mathcal{V} \to \mathcal{H}_v \) (or \( \boldsymbol{e}^{(t)}: \mathcal{T} \to \mathcal{H}_t \)) such that the learnt representation \( \boldsymbol{h}^{(v)} = \boldsymbol{e}^{(v)}(\boldsymbol{x}^{(v)}) \) (or \( \boldsymbol{h}^{(t)} = \boldsymbol{e}^{(t)}(\boldsymbol{x}^{(t)}) \)) captures essential information about the input. Remarkably, it was observed, in both computer vision (CV) and natural language processing (NLP) that such encoders trained on very large scale heterogeneous data can be effective for many downstream tasks (e.g., via linear projection, finetuning, etc.) (Devlin et al., 2018, He et al., 2022). This phase of learning is often referred to as pretraining and the final model is referred to as a foundation model.
Foundation models initially focused on developing "universal" encoders capable of extracting meaningful representations from unimodal data—be it images, videos, or text—in diverse contexts. Self-supervised learning techniques dominate the state-of-the-art in unimodal representation learning, where the unsupervised data is modified to fit the supervised learning framework (Devlin et al., 2018, He et al., 2022). The primary goal of these models is to excel at various unimodal downstream tasks (with small modifications). For text, this includes sentiment classification, question answering, and text retrieval. For images, tasks such as image classification, object detection, and segmentation are common. Despite their unimodal nature, these models play a crucial role in multimodal learning. In the following subsections, we will explore some of the key unimodal encoders that have been instrumental in constructing multimodal models.
Text Encoders
Bidirectional Encoder Representations from Transformers (BERT)
BERT (Devlin et al., 2018) is a widely adopted encoder model for text data. It uses powerful pre-training approach that allows the model to understand context from both left and right sides of a word simultaneously.
BERT's architecture is based on the Transformer model, specifically using only the encoder portion. It consists of multiple layers of bidirectional Transformer blocks.
In the pre-training stage, BERT is trained on a large corpus of unlabeled text data using two unsupervised tasks:
- Masked Language Model (MLM): Given an input sequence, BERT randomly masks 15% of the tokens and attempts to predict these masked tokens based on the surrounding context. This task forces the model to learn bidirectional context.
- Next Sentence Prediction (NSP): The model predicts whether a given sentence pair appears consecutively in the original text. This task helps BERT understand the relationship between sentences.
BERT uses special tokens to structure its input:
- [CLS] at the start of each sequence (used for classification tasks)
- [SEP] to separate sentences
- [MASK] for the MLM task
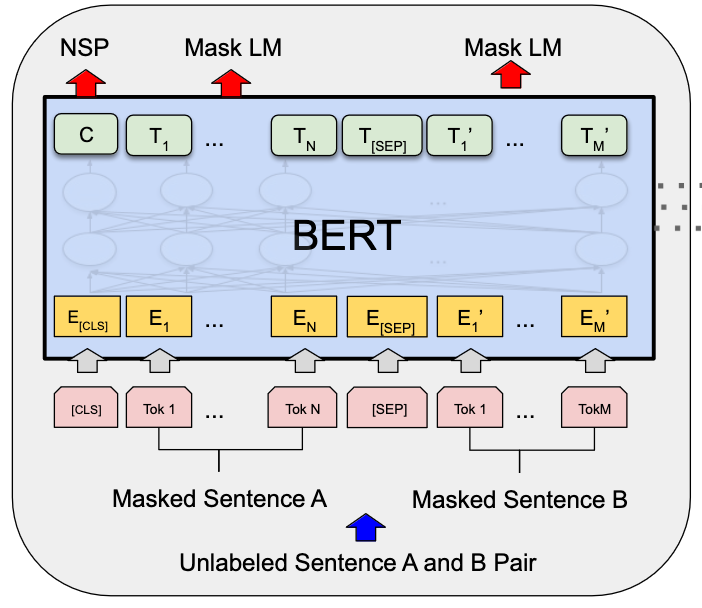
After pre-training, BERT can be fine-tuned on various downstream NLP tasks with minimal task-specific modifications, making it a versatile and powerful tool in NLP.
Text-to-Text Transfer Transformer (T5)
T5 (Text-to-Text Transfer Transformer) (Raffel et al., 2020) is another powerful text encoder that is trained on a unified text-to-text framework. The most important difference between the T5 model with respect to then existing models is that all NLP tasks are cast as text-to-text tasks, where the input and output are both text. This approach allows T5 to handle a wide range of NLP tasks with a single model architecture, facilitating better transfer learning and simplifying the process of applying the model to new tasks.
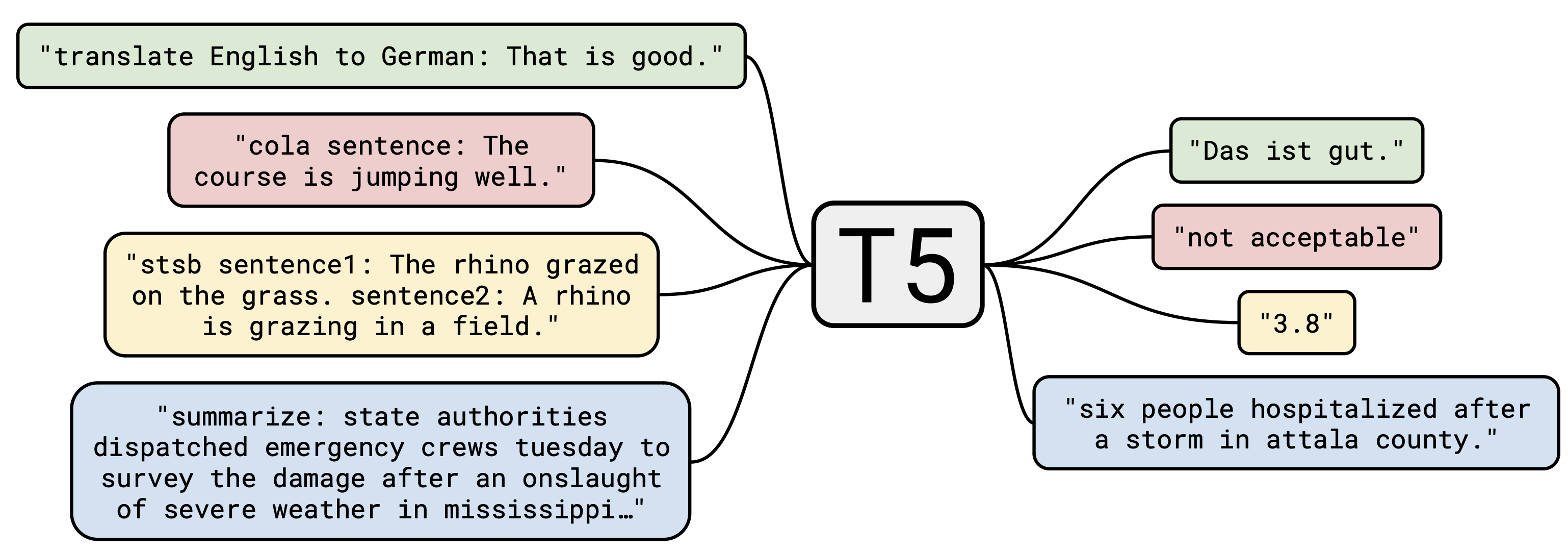
The key characteristics of T5 are as follows:
- Unified Framework: All NLP tasks are cast as text-to-text tasks.
- Architecture: Transformer encoder-decoder architecture instead of the encoder-only architecture of BERT.
- Pre-training: Pre-trained on a large-scale dataset (Colossal Clean Common Crawl) using masked-LM and next word prediction objectives.
- Fine-tuning: Fine-tuned on downstream tasks using a text-to-text framework (minimal or no change to the architecture).
T5's innovative approach to unifying NLP tasks and its powerful pre-training on a massive dataset have made it a significant milestone in the development of language models, paving the way for more flexible and generalizable NLP systems.
Vision Encoders
Discrete Representations
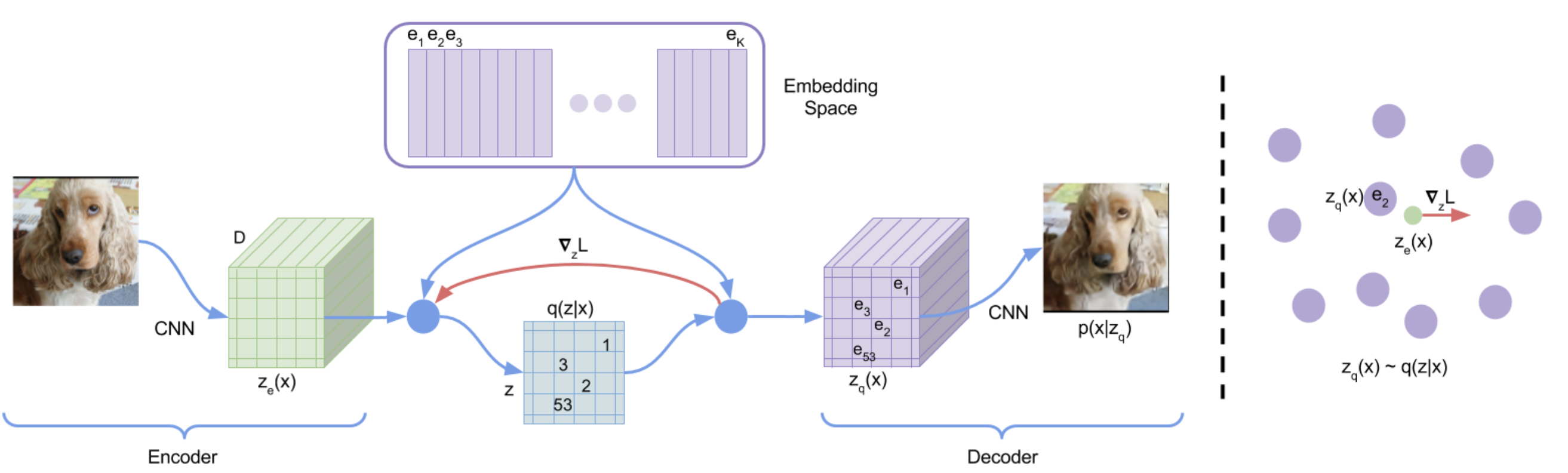
Vector Quantized-Variational AutoEncoder (VQ-VAE)
The idea of VQ-VAE ((Van Den Oord et al., 2017)) is to learn a VAE with discrete latent space. VQ-VAE is constructed as follows:
First, consider the VAE framework. Let \( q(\boldsymbol{z}|\boldsymbol{x}) \) be the posterior and \( p(\boldsymbol{x}|\boldsymbol{z}) \) be the likelihood. The encoder neural network is denoted by \( \boldsymbol{z}_e \). The encoder tries to map images into one of the \(K\) embedding vectors represented by \( \boldsymbol{e}_1, \dots, \boldsymbol{e}_K \). The posterior \( q(\boldsymbol{z}|\boldsymbol{x}) \) is modeled as a categorical distribution over \( \boldsymbol{e}_1, \dots, \boldsymbol{e}_K \), and is parameterized as follows:
Now, denote by \( \boldsymbol{z}_q(\boldsymbol{x}) = \boldsymbol{e}_{\arg\min_{j} \| \boldsymbol{z}_e(\boldsymbol{x}) - \boldsymbol{e}_j \|} \), the quantized latent variable. VQ-VAE assumes that the prior \( p(\boldsymbol{z}) \) is a uniform distribution over \( \boldsymbol{e}_1, \dots, \boldsymbol{e}_K \). Then, the KL-term of the VAE loss becomes a constant \( KL(q(\boldsymbol{z}|\boldsymbol{x}) || p(\boldsymbol{z})) = \log K \), which avoids posterior collapse by construction. Finally, the objective is to minimize the following loss:
where \( {\rm sg}[\cdot] \) is the stop gradient operator.
After VAE training, the uniform prior is discarded and a new \( p(z) \) is learned using the distribution of \( \boldsymbol{z}_q(\boldsymbol{x}) \) with PixelCNN (an autoregressive model for pixel generation) (Salimans et al., 2017).
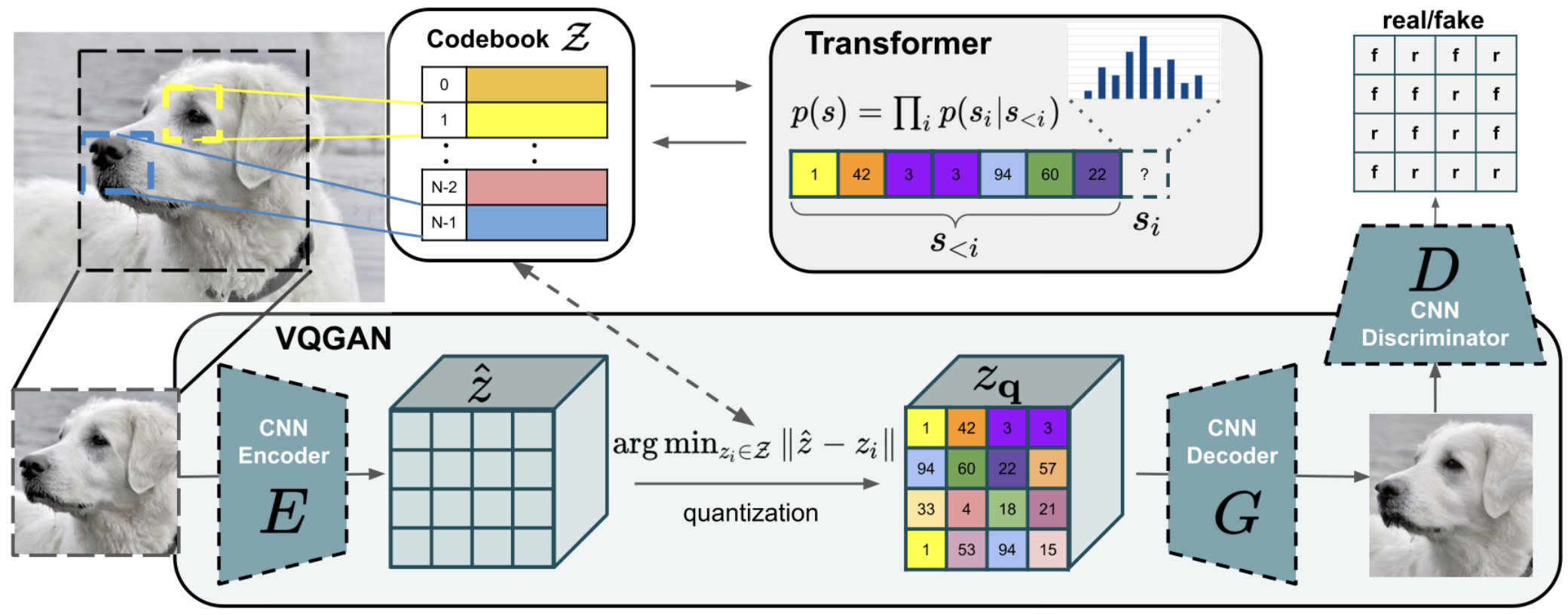
Vector Quantized-Generative Adversarial Network (VQ-GAN)
VQ-GAN ((Esser et al., 2021)) makes several changes on top of VQ-VAE. Mainly, it replaces the VAE decoder with a GAN generator, adds an adversarial loss for the generator, and uses a transformer decoder instead of PixelCNN for learning the prior.
Continuous Representations
Vision Transformer (ViT)
The Vision Transformer is the most widely adopted architecture for vision encoders used in multimodal learning. The main idea of the Vision Transformer is to treat an image as a sequence of tokens and use transformer to learn representations. To that end, an image is divided into fixed-size non-overlapping patches. These patches are then flattened and projected into a sequence of vectors, similar to token embeddings in language models. A [CLS] token \( \boldsymbol{x}_{{\rm [CLS]}} \) is prepended to the input sequence, and \( \boldsymbol{h}_{\rm [CLS]} \) is used as the representation of the image.
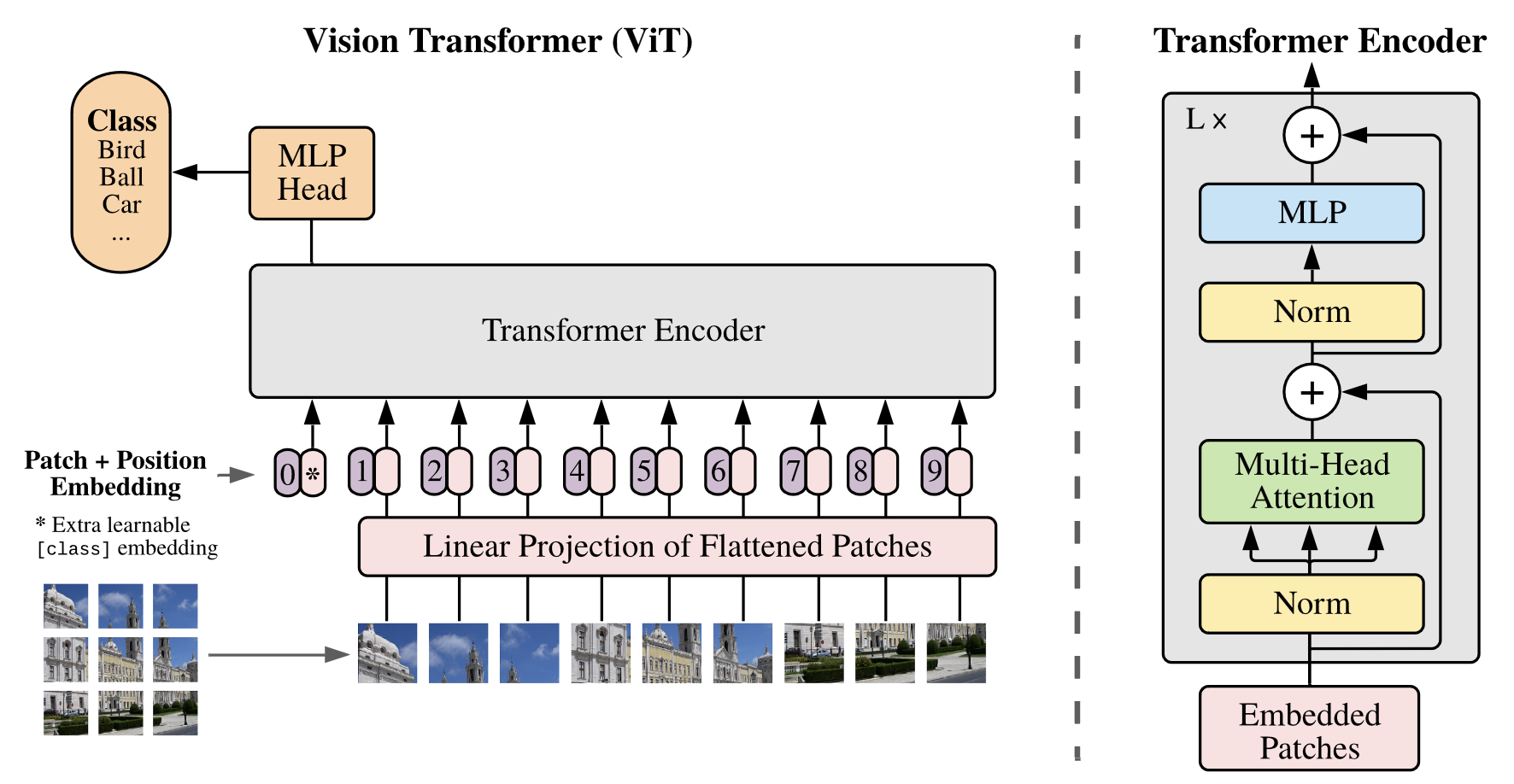
Masked Autoencoders (MAE)
Masked Autoencoder is a self-supervised representation learner, trained by predicting masked tokens just like BERTs. MAE, first, divides an image into fixed-size non-overlapping patches and randomly removes more than 75% of these patches. The remaining patches are fed into the Vision Transformer encoder. The encoded patches and mask tokens are then fed into the decoder. The training objective is the reconstruction loss between the original image and the reconstructed image. The output of the encoder can be used as the representation of the image.
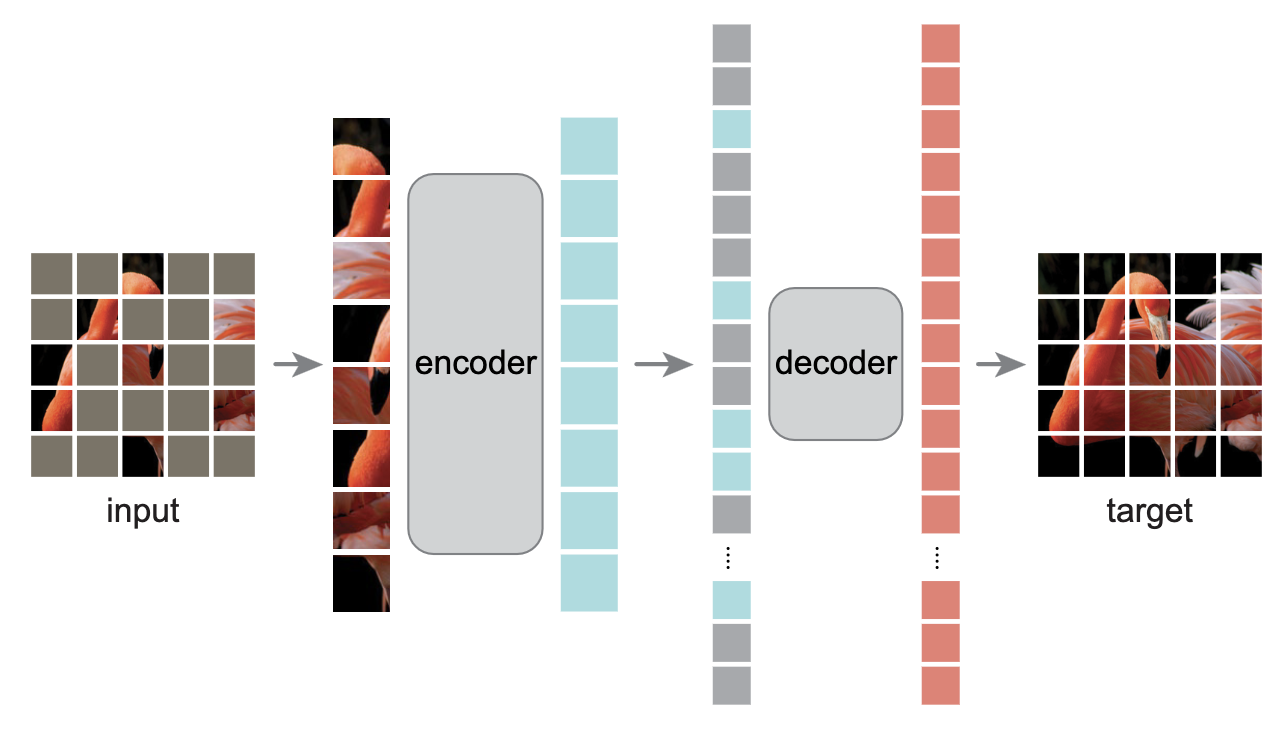
Multimodal Representation Learning
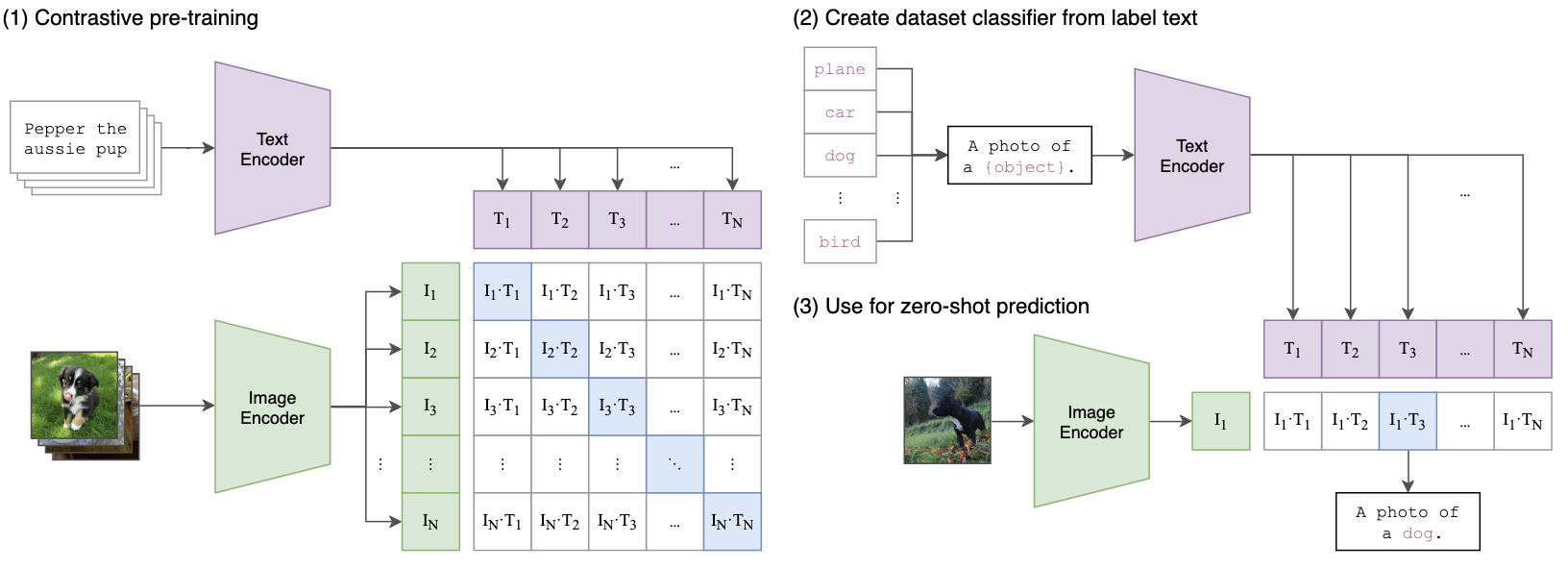
Contrastive Language-Image Pre-training (CLIP)
Contrastive Language-Image Pre-training (CLIP) is one of the first large-scale multimodal representation learning approach. The researchers behind CLIP constructed an extensive dataset comprising 400 million image-text pairs, laying a robust foundation for their model. At its core, CLIP utilizes two main components: a vision encoder \((\boldsymbol{e}_v: \mathcal{V} \to \mathcal{H})\) and a text encoder \((\boldsymbol{e}_t: \mathcal{T} \to \mathcal{H})\). The vision encoder is based on a Vision Transformer (ViT) architecture, while the text encoder employs a decoder-based transformer.
The training objective of CLIP is designed to maximize the similarity between matched image-text pairs while minimizing the similarity between unmatched pairs. Specifically, for a batch of image-text pairs \((\boldsymbol{x}^{(v, i)}, \boldsymbol{x}^{(t, i)})_{i=1}^N\), the optimization problem can be formulated as:
This objective function encourages the model to learn meaningful representations that capture the common semantic information between images and their corresponding textual descriptions. CLIP was shown to have strong generalization capabilities for many vision tasks (e.g., zero-shot image classification).
LiT: Zero Shot Transfer with Locked-image text Tuning
LiT (Locked-image text Tuning) builds upon the foundation laid by CLIP while introducing some key innovations. Unlike CLIP, which trains both the vision and text encoders from scratch, LiT employs a supervised pre-trained vision encoder (ViT-g/14) and only trains the text encoder from scratch. This approach demonstrates that utilizing pre-trained vision encoders yields superior results compared to training both encoders from scratch.
LiT maintains the same contrastive learning objective as CLIP, focusing on maximizing the similarity between matched image-text pairs. The vision encoder used in LiT was pre-trained on JFT-3B, a massive dataset of 30 billion semi-automatically labeled images privately collected by Google. This pre-training on a diverse and extensive dataset contributes significantly to the model's performance and generalization capabilities.
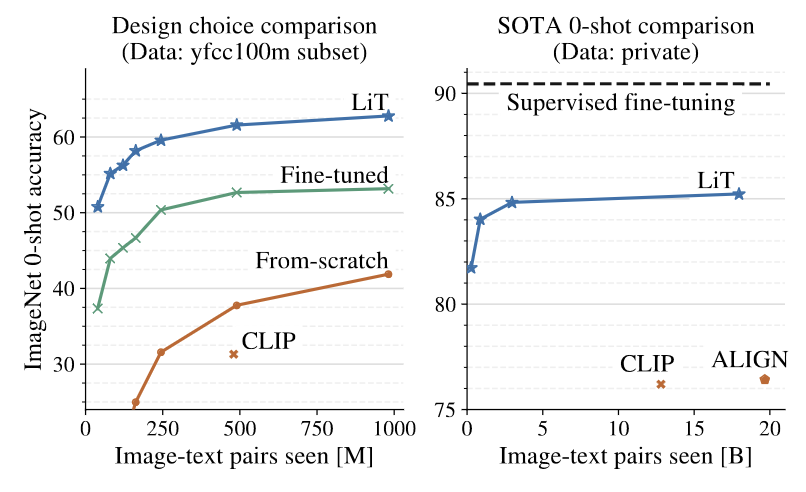
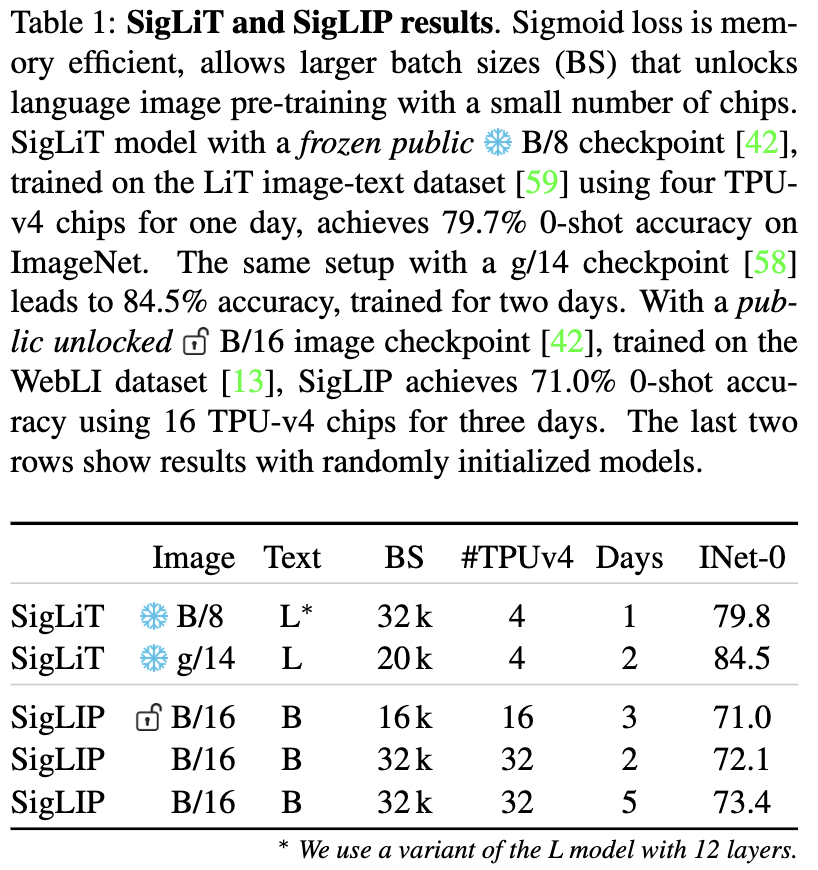
SigLIP: Sigmoid Loss for Language Image Pre-Training
SigLIP addresses some of the challenges faced by previous contrastive learning approaches like CLIP and LiT. These earlier methods suffered from significant memory and communication overhead due to their loss function design. For instance, CLIP required 12 days of training on 256 V100 GPUs. The primary issue stemmed from the need to materialize a large (B × B) matrix of pairwise similarities to compute the loss, where B is the batch size (32k in CLIP's case).
SigLIP's key innovation lies in replacing the softmax function with a sigmoid in the loss function. This modification allows for more efficient computation and faster training. In SigLIP's approach, positive pairs \((\boldsymbol{x}^{(v,i)}, \boldsymbol{x}^{(t,i)})\) are assigned a label of 1, while negative pairs \((\boldsymbol{x}^{(v,i)}, \boldsymbol{x}^{(t,j)}), j \neq i\) are labeled as 0. The resulting loss function is:
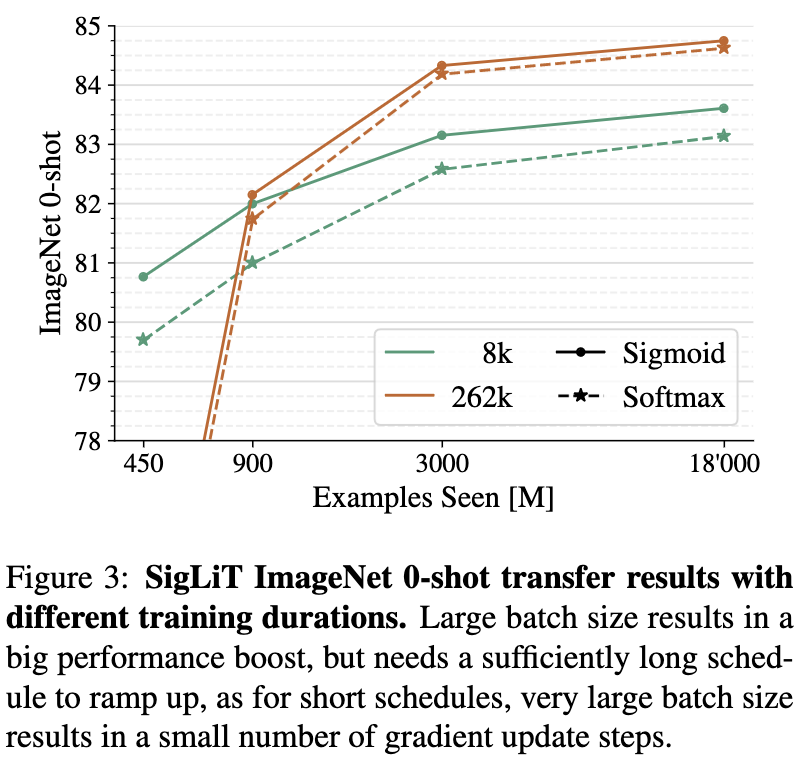
This reformulation led to a significant reduction in training time, with SigLiT (the implementation of SigLIP) requiring only 2 days of training on 4 TPUv4s.
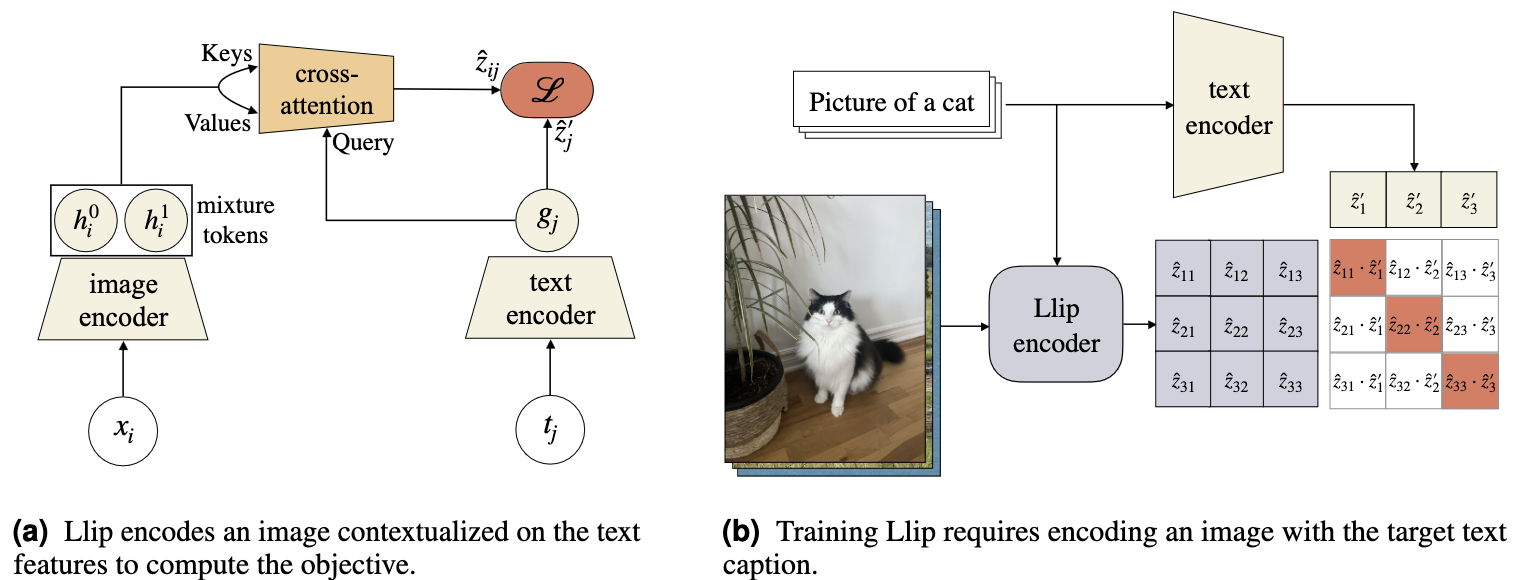
Llip: Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Llip introduces a novel approach to address the challenge of caption diversity in vision-language pretraining. Recognizing that a single image can have multiple valid captions, Llip proposed to modify the image representation based on the caption. This method allows the model to capture the nuanced relationships between images and their various textual descriptions more effectively.
In Llip's architecture, \(\boldsymbol{h}_{\rm [CLS]}^{(t, i)}\) represents the overall text embedding, and \((\boldsymbol{h}_n^{(v, i)})_{n=1}^{N_t}\) denotes the individual image patch embeddings of the i-th paired sample. The model employs a text query matrix \(\boldsymbol{W}_q^{(t)}\) and image key and value matrices \(\boldsymbol{W}_k^{(v)}\) and \(\boldsymbol{W}_v^{(v)}\). The attention mechanism is then applied as follows:
The resulting loss function for Llip is:
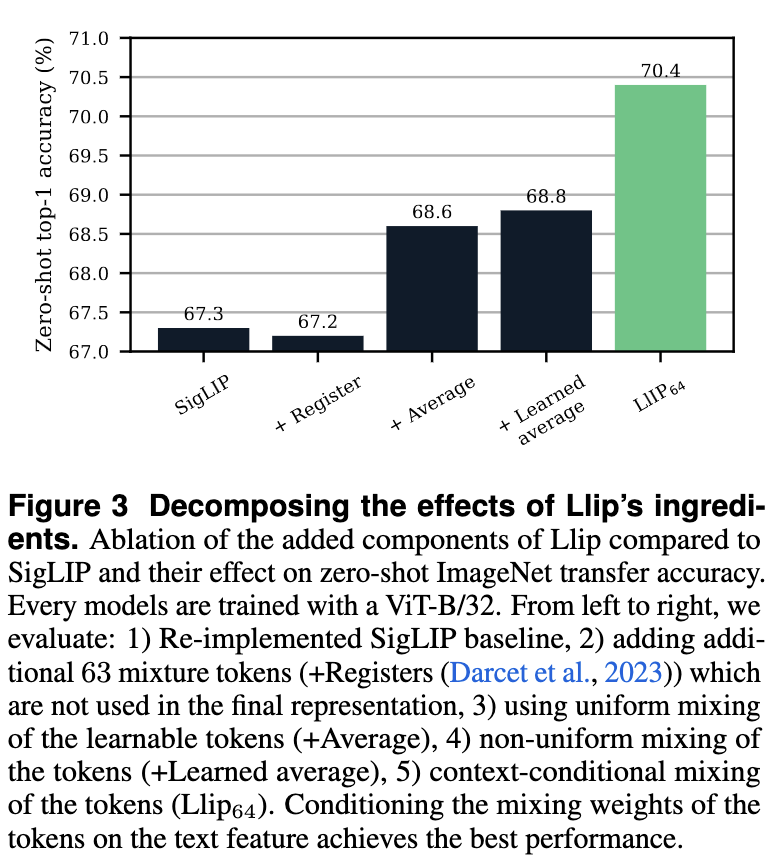
The above ablation study shows that Llip results in slightly better performance over SigLIP.
Conclusion
Vision-language representation learning has evolved rapidly from simple unimodal encoders to sophisticated multimodal systems. The progression from BERT and ViT to CLIP and its variants demonstrates the power of contrastive learning in bridging vision and language modalities. These advances have opened new possibilities for AI systems that can understand and reason about both visual and textual information, paving the way for more intuitive human-AI interactions.
References
[Devlin et al., 2018] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[Dosovitskiy et al., 2020] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
[Esser et al., 2021] Esser, P., Rombach, R., & Ommer, B. (2021). Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12873-12883).
[He et al., 2022] He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000-16009).
[Lavoie et al., 2024] Lavoie, S., Kirichenko, P., Ibrahim, M., Assran, M., Wildon, A. G., Courville, A., & Ballas, N. (2024). Modeling caption diversity in contrastive vision-language pretraining. arXiv preprint arXiv:2405.00740.
[Raffel et al., 2020] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1-67.
[Radford et al., 2021] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[Van Den Oord et al., 2017] Van Den Oord, A., Vinyals, O., & Kavukcuoglu, K. (2017). Neural discrete representation learning. Advances in neural information processing systems, 30.
[Zhai et al., 2022] Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., & Beyer, L. (2022). LiT: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18123-18133).
[Zhai et al., 2023] Zhai, X., Mustafa, B., Kolesnikov, A., & Beyer, L. (2023). Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 11975-11986).